 Pourquoi le projet pilote POPGEN ?
Pourquoi le projet pilote POPGEN ?
Le développement de la médecine génomique qui va permettre une meilleure prise en charge des patients est possible grâce aux technologies de plus en plus innovantes et rapides qui permettent de lire une partie ou l’ensemble de notre génome.
|
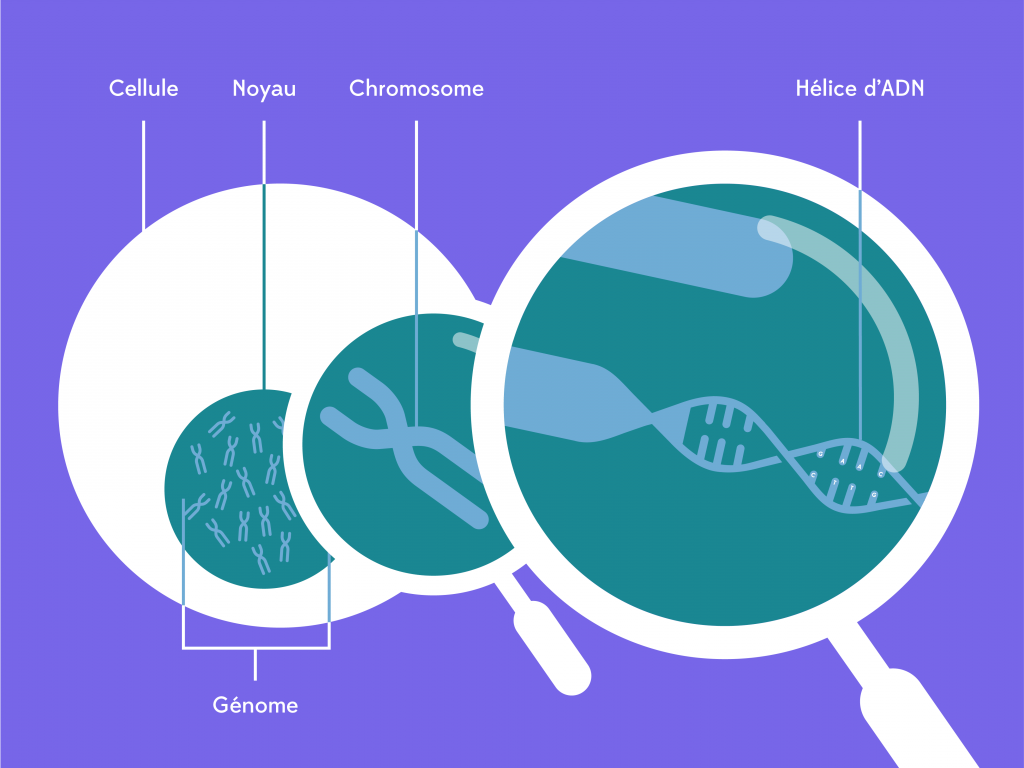
Le génome est l’ensemble de l’ADN (Acide Désoxyribonucléique) qui constitue nos chromosomes. L’ADN s’écrit à l’aide d’un alphabet de quatre lettres A T G C (A pour Adénine, C pour cytosine, T pour thymine et G pour guanine), appelés nucléotides. Composé de plus de 3 milliards de lettres, le génome d’une personne remplirait l’équivalent de 400 dictionnaires. |
|
Le séquençage du génome consiste à lire l’ADN, c’est-à-dire la succession des lettres qui s’enchainent dans un ordre particulier. |

|
L’ADN est le même dans toutes les cellules d’un individu et est propre à cet individu. Entre deux individus, on observe des différences sur environ une lettre sur mille (soit environ 3 millions de variations). Ces variations observées entre les individus sont responsables des différences de couleur de cheveux ou des yeux, par exemple, et dans certains cas, elles peuvent être impliquées, directement ou en tant que facteurs de risque, dans la survenue de pathologies.
Dans le cadre de la prise en charge d’un patient, l’objectif du séquençage est de permettre de repérer les variations génétiques qui pourraient expliquer sa maladie. Pour identifier les endroits du génome du patient où il existe des variations, son génome est comparé à un génome humain de référence.
Une grande majorité de ces variations sont des variations dites neutres, c’est-à-dire sans effet sur la maladie, qu’on pourra éliminer d’emblée de l’analyse. Pour faire le tri entre les variations neutres, plutôt fréquentes, et les variations potentiellement impliquées dans la maladie, plus rares, le principe est très simple : il suffit de regarder la fréquence de la variation dans la population générale. Pour ce faire, il faut disposer d’une base de données répertoriant ces variations et leurs fréquences sur le territoire français.
Un premier travail de ce type a déjà été réalisé dans quelques régions françaises, et a permis à plusieurs équipes d’avancer sur leurs projets. Ce premier panel de témoins a également confirmé le besoin d’avoir des données de références provenant de notre population pour que les recherches soient les plus précises possible. Ce panel ne couvrant qu’une petite partie du territoire, il était impératif pour les futurs protocoles de soins d’avoir une base de données couvrant le mieux possible le territoire métropolitain. C’est là l’objectif principal de la recherche sur la « Diversité génomique de la population française », POPGEN : constituer cette base de référence nationale, dans le cadre du plan France Médecine Génomique 2025.